
This post concerns an experimental internal-BBC-only project designed to allow users to collectively describe, segment and annotate audio in a Wikipedia-style fashion. It was developed by the BBC Radio & Music Interactive R&D team – for this project consisting of myself, Tristan Ferne, Chris Bowley, Helen Crowe, Paul Clifford and Bronwyn Van Der Merwe. Although the project is a BBC project, all the speculation and theorising around the edges is my own and does not necessarily represent the opinion of my department or the BBC in general.
It’s officially my last day at the BBC today, but with the permission of my outgoing boss Mr Daniel Hill I’m going to make the very best use of it by talking about a project that we’ve been working on for the last few weeks. I consider it one of the most exciting projects I’ve ever worked on, and BBC Radio & Music Interactive one of the only places in the world where I would have been able to have done so.
If you’re impatient, you should probably skip straight to the clumsy screencasts I’ve done to illustrate the project – playing an annotated programme (4 Mb) and editing / annotating a programme (4Mb).
But for everyone else, maybe a little context. The media landscape is changing incredibly quickly – ten or twenty years ago in the UK you might have had a choice of a dozen or so radio and television stations broadcasting at any given time. Over the last decade that’s grown to hundreds of stations, plus a variety of on-demand services like Sky Box Office. Over the next few decades, it’s pretty clear that the massive archives of content (that every broadcaster in the world has accrued over the last seventy or eighty years) will start to appear on-demand and on the internet. You can already see the evidence of consumer interest in the sheer number of conventional stations that broadcast repeats, and on the international sales of DVDs across the world. An on-demand archive is going to make the number of choices available to a given individual at any point almost completely unmanageable. And then there’s the user-generated content – the amateur and semi-professional creations, podcasts and the like that are proliferating across the internet. In the longer term there are potentially billions of these media creators in the world.
All of this choice, however, creates some significant problems – how on earth are people expected to navigate all of this content? How are they supposed to find the specific bit of audio or video that they’re looking for? And how are they supposed to discover new programmes or podcasts? And it gets more complicated than that – what if what you’re not looking for is a complete coherent half-hour programme, but a selection of pertinent clips – features on breaking news stories, elements in magazine programmes, particular performances from music shows?
In the end, the first stage in making any of these processes possible is based on the availability of information about the audio or video asset in question – metadata – at as granular a level as possible. And not only about that asset, but also about its relationship to other assets and services and other information streams that give individuals the ability to explore and investigate and assess the media they’ve uncovered.
The project we undertook was focused on Annotatable Audio (specifically, but not exclusively, of BBC radio programming) – and we decided to look in an unorthodox direction – towards the possibilities of user-created annotation and metadata. We decided that we wanted to develop an interface that might allow the collective articulation of what a programme or speech or piece of music was about and how it could be divided up and described. Our first ideas looked for approaches similar to del.icio.us, Flickr or our own Phonetags – which create collective value by accreting the numerous annotations that individuals make for their own purposes. But after a fascinating discussion with Jimmy Wales, we decided to think about this in a different way – in which (just like Wikipedia) individuals would overtly cooperate to create something greater and more authoritative.
So here’s what we’ve come up with. First off, imagine yourself as a normal user coming to a page about a particular programme or speech. What you see is a simple interface for playing and scrubbing through the audio at the top of the page with marked ‘segments’ highlighted. If you hover over those segments they brighten up and display the title of that section. If you click on them, it starts the audio playing from that point. This correlates to the sections below which could be filled with any amount of wiki-style content – whether that be links or transcripts or background information or corrections or whatever. Beneath that are tags that users have added to describe the programme concerned. If you click on any of the segment permalinks to the left it starts the audio at that point and changes the URL to an internal anchor so you can throw around links to chunks of a programme or a speech. So basically you get a much richer and fuller experience of the audio that you’d get by just listening to it in a media player. Here’s a screen cap:
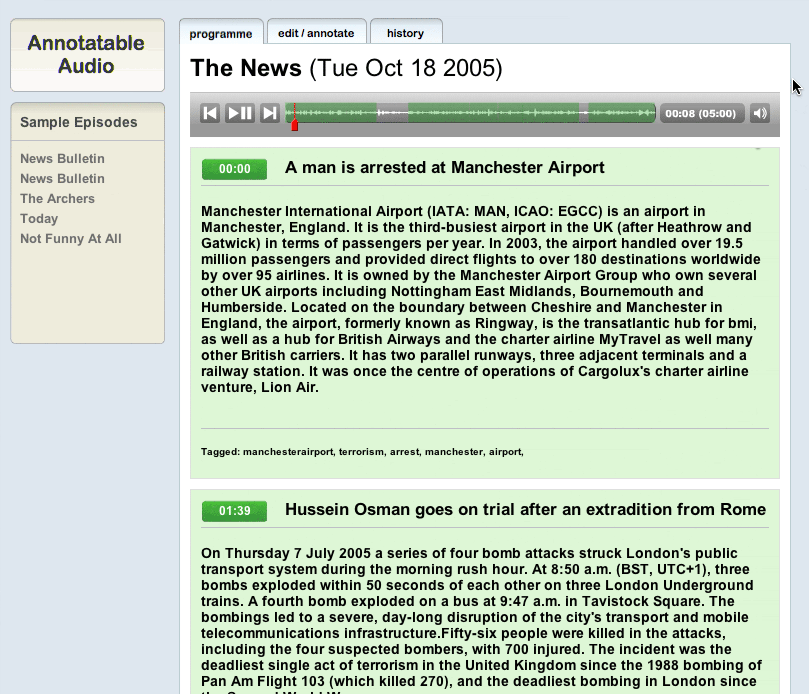
But it gets much more exciting when you actually delve a bit deeper. If you want to edit the information around a piece of audio, then just like on a wiki you just click on the ‘edit / annotate’ tab. This brings you up a screen like this:
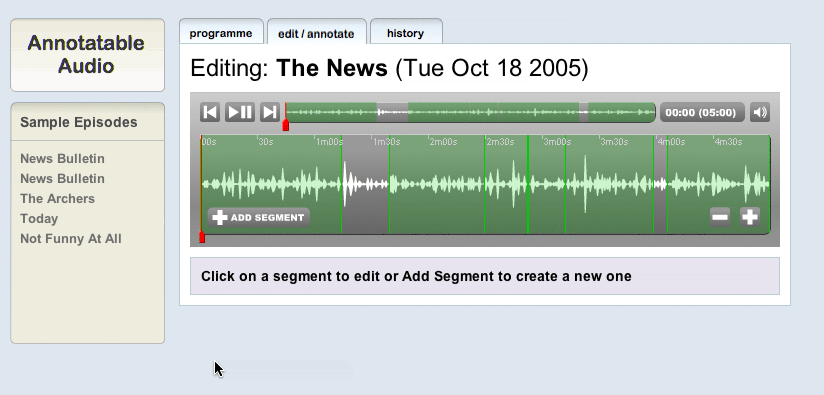
Here you can zoom into the wave form, scrub around it, and decide either to edit a segment or create a new segment. Once you’ve decided (in this walkthrough I decided to edit a pre-existing segment) you simply click on it, at which point the editing interface appears:
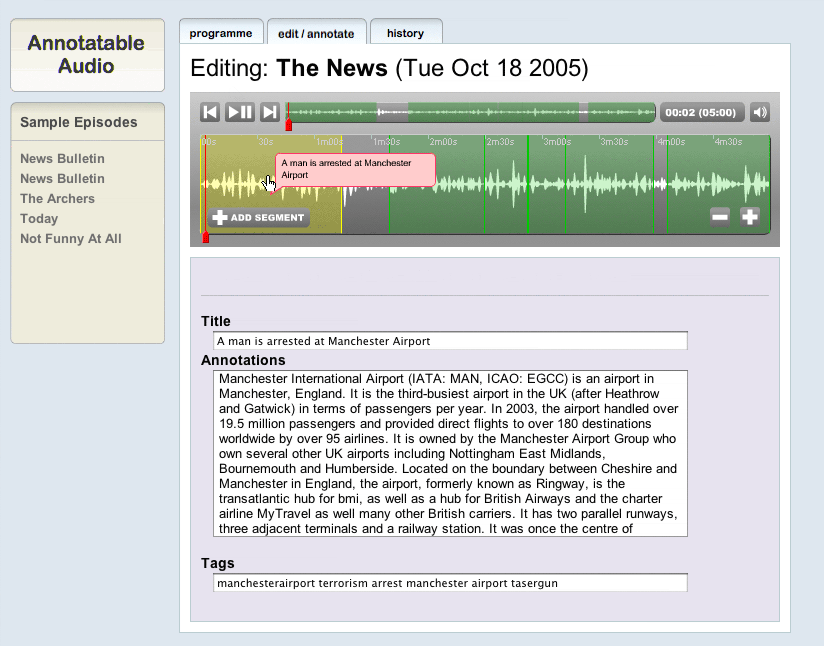
And on this screen you can change the beginning and end points of the audio by simply clicking and dragging, you can change the title to something more accurate, add any wiki-style content you wish to in the main text area and add or delete the existing fauxonomic metadata. If you want to delete a segment you can. If you need to keep digging around to explore the audio, you can do so. It’s all amazingly cool, and I’m incredibly proud of the team that made it.
This final screen represents that last core aspect of wiki-like functionality – a history page that allows you to revert back to previous versions of the annotations if someone has defaced the current version:
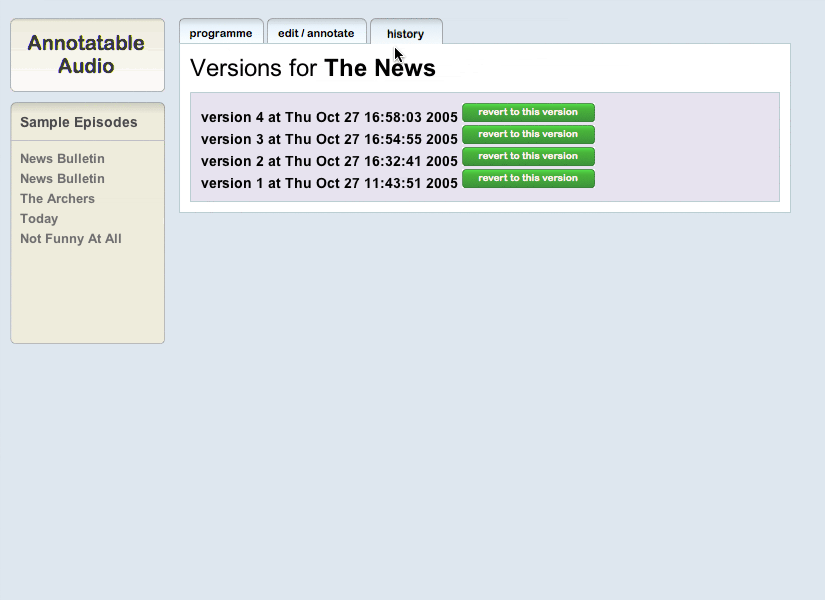
So that’s the core parts of the project – a demonstration of a functional working interface for the annotation of audio that’s designed to allow the collective creation of useful metadata and wikipedia-like content around radio programmes or speeches or podcasts or pieces of music. If you’ve worked through the rest of this piece and managed to not watch the screencasts now, here are the links again – although be warned, they are a few Mb in size each. The first one shows the functionality of the playback page(8 Mb) and how people might use the information to navigate through audio. The second shows someone editing the page, editing a segment and adding a new segment (4 Mb), and it really shows off Chris Bowley‘s astonishing work on the Flash components and how it connects to Helen Crowe’s Ajaxy HTML.
As always with projects from the R&D team, the Annotatable Audio project is unlikely to be released to the public in its current form. We’re using it as a way of testing out some of these concepts and approaches – some of which will probably manifest in upcoming products in one way or another. In the meantime if you want to know more about the project or you’re inside the BBC and would like a play, then either leave a comment below or contact the awesome Tristan.Ferne {at the domain} bbc.co.uk who’s going to be running the project now I’ve left.
Anyway, I’d just like to take this final opportunity again to say thank you to the BBC and to all the people I’ve worked with to make cool stuff. It’s been a blast and I genuinely couldn’t be happier with the final project we worked on together. You guys rock. But now… Something new!
And just to give you the disclaimer one more time. The Annotatable Audio project was developed by Tom Coates, Tristan Ferne, Chris Bowley, Helen Crowe, Paul Clifford and Bronwyn Van Der Merwe. Although the project is a BBC project, all the speculation and theorising around the edges is my own and does not necessarily represent the opinion of my department or the BBC in general.
24 replies on “On the BBC Annotatable Audio project…”
This is really spectacular. Looks brilliant. Nice execution on a really solid idea.
This is really interesting. I’m intrigued as to what politics might eventually end up driving the idea though. Do you see any dangers?
On the one hand I am concerned that wiki-based technologies like this will represent a privatisation (that is, individuation) of our news interests to the extent that we only hear the stories that we want. But then there is the paradox that it is the BBC developing this; is there an authoritarian streak, or is it the publicity-conscious BBC trying to show that they’re not being authoritarian?
I guess my key question is: do people think this kind of technology will enhance coverage of the news, or diminish it, or neither?
tom – very interesting, how likely is it we see something like this any time soon?
(linked you up, http://feed.proteinos.com/item/3755)
Really interesting project! I look forward to seeing where this goes in the future. Thanks for sharing this.
Indeed. Thanks for sharing this. I feel like I’ve seen the future–and knowing how things go, that means I may still be able to understand what people are talking about next week.
I don’t know if you’ve posted the answer to my next question already, and I missed it, but: what are your plans? It sounds like you’re out of a job? ?? I hope not! If so, are you going to wait a while before the next one? Or do you have other plans? At least, ones that you could tell us about?
Have a look at http://www.annodex.net – there
is a nice complementarity with this work.
i started thinking about something similar after reading about Jon Udells experiments jumping into and ‘quoting’ audio content.
guess there is a streak in me at the moment that is ‘annotate everything’ :).
this does look like wonderful work though, hope someone runs with it….
mark.
That’s amazing… Audio scrubbing in flash… That’s hard. The BBC interactive team rock, what can I say.
God speed on your new job!
Andrew
Interesting, similar to an idea that we were pushing around some time ago, keep up the good work!
let users tend the garden. makes sense.
I’m curious — in Flickr, you can see notes by rolling over the photo. They appear as tiny frames.
I can’t tell from the above — how do annotated areas show up on the audio? Is it like the little doodads that pop up during extended DVDs (click on the rabbit to learn more about how we filmed this scene in Holy Grail)?
It’s very very interesting, and I’d love to eventually see something similar extend to video.
I wonder if over-annotation might be a problem in the future… selecting what you read about an item might be an important tool, if this catches on the way it should.
We’re beginning to work on a similar project at Ourmedia.org (the nonprofit home for grassroots media). And, unlike the venerable Beeb, we’re an open-source project that believes in sharing the source code with anyone who wants to participate. (Jon Udell and Doug Kaye have agreed to advise us. We’re calling it a rich media clipping service for audio and video.)
So, if you’d like to participate, drop me a line: jd@well.com
Good luck, Tom, fascinating work!
Is the pool of volunteers going to be limited to only UK people? Aunty blocks much of her multimedia output to non-UK IP addresses.
Wow!
Like many others, I’m sure, I think the applications of this projects are bountiful, to say the least. Excellent work.
This looks great, I can’t wait to see what the podcasting community do with this when they get their hands on it 🙂
This is freaky- one of those all too common moments when you step outside the monolith and look back inside to see someone in an adjecent cell doing just the same thing you are.
Have you heard of the ‘Spoken Word’ project that BBC archives, Galsgow Caledonian Uni, and a couple f US unis are working on. It does almost exactly the same thing- it’s just the application is slightly different- they’re using it as a teaching aid in complex legal cases.
http://www.at.northwestern.edu/spoken/p04annotation.html
http://www.spokenword.ac.uk/resources.php
Little flakey at this precise moment due to a rebuild, but it works well most of the time.
Hi everyone,
Just a follow up from Ant’s post (thanks Ant!). We have re-structured our Spoken Word web site at Glasgow Caledonian University recently, so information about our Audio Annotation tool is now located at http://www.spokenword.ac.uk/annotation.php
We welcome comments, feedback, collaboration!
What a great idea… Possibilities are mind-boggling.
Hmm, very interesting. I’ve been toying around a term “broadcast content deep links”. Essentially, we need a common metadata structure to refer to once aired content resident on one’s PVR and/or accessible as on demand content – on a sustainable basis. That calls for deeplinks into broadcast content (including ads) that do not die but rather help pull no longer -published content from the archives. Anyone done that somewhere already?
Very engaging approach to the annotation issue. My group here at Northwestern University Academic Technologies has built a suite of tools to annotate all objects including audio and video. We have aligned audio to the word level then drill in to select the bits we want and comment. Comments may be shared or not. We can also create customized templates to systematically study the object (albeit audio or video). Results output as xml. See projectpad.northwestern.edu for a download. How to encourage cross-fertilization of effort here?
This may sound great and a little more complicated, too. But how many people want to spend time editting waveforms? curious.
I’m not sure I understand your question.
WOW! Just the people! Can we meet and talk about art applications for this technology? We are artists working in the field of peace education, free speach and social responsability. Based in S.London.
Really interesting project! I look forward to seeing where this goes in the future.